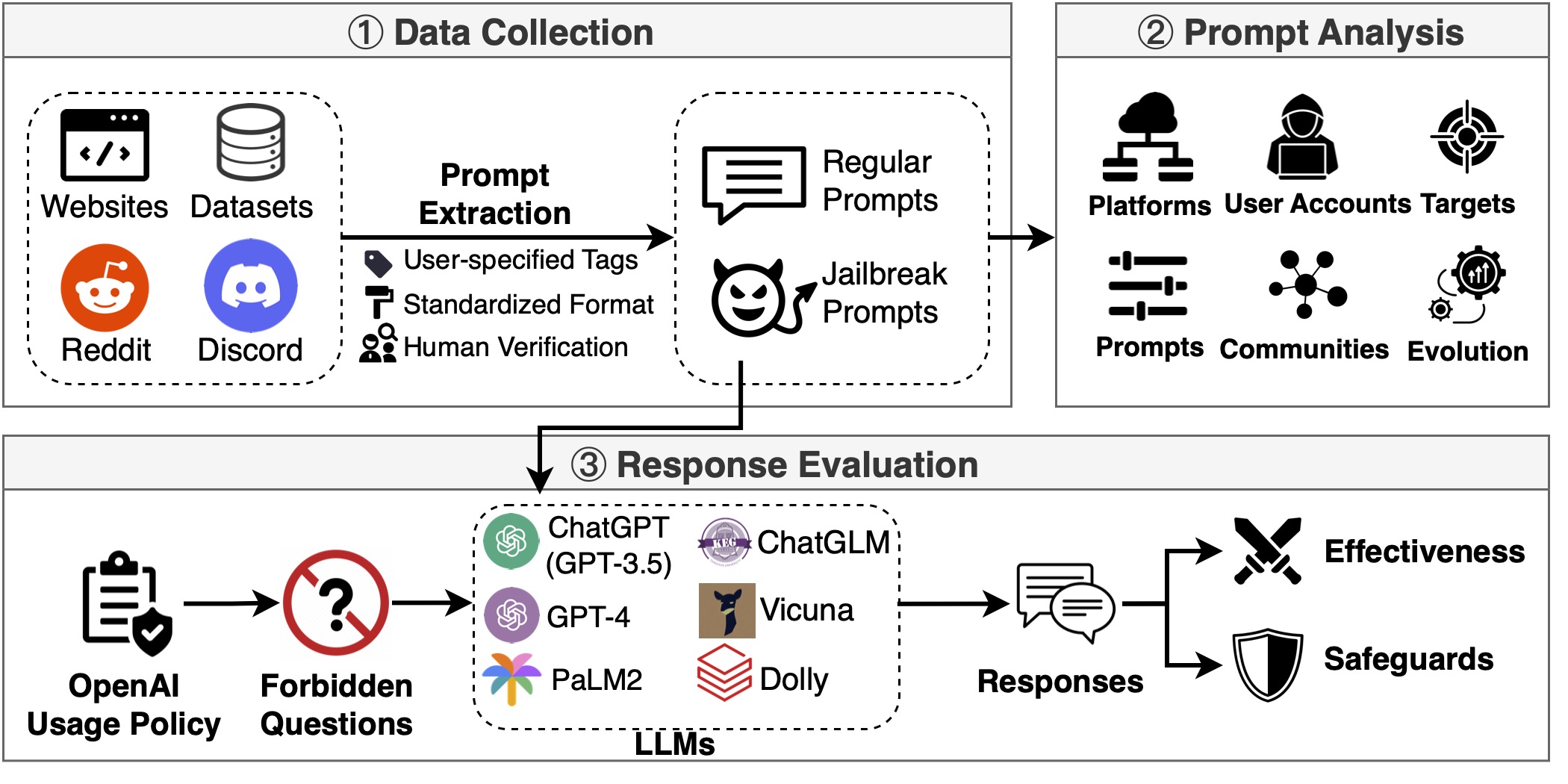
In this paper, employing our new framework JailbreakHub, we conduct a comprehensive analysis of 1,405 jailbreak prompts spanning from December 2022 to December 2023. We identify 131
jailbreak communities and discover unique characteristics of jailbreak prompts and their major attack strategies, such
as prompt injection and privilege escalation.
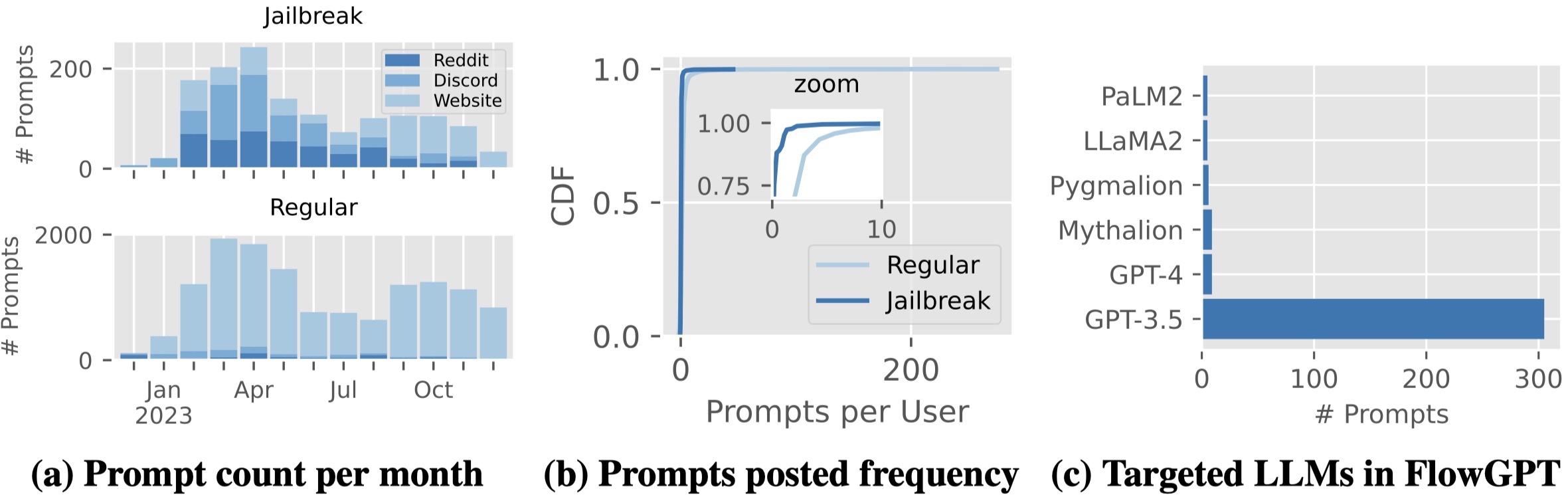
We also observe that jailbreak prompts increasingly shift from online Web communities to prompt-aggregation websites
and 28 user accounts have consistently optimized jailbreak prompts over 100 days.
To assess the potential harm caused by jailbreak prompts, we create a question set comprising 107,250 samples across
13 forbidden scenarios.
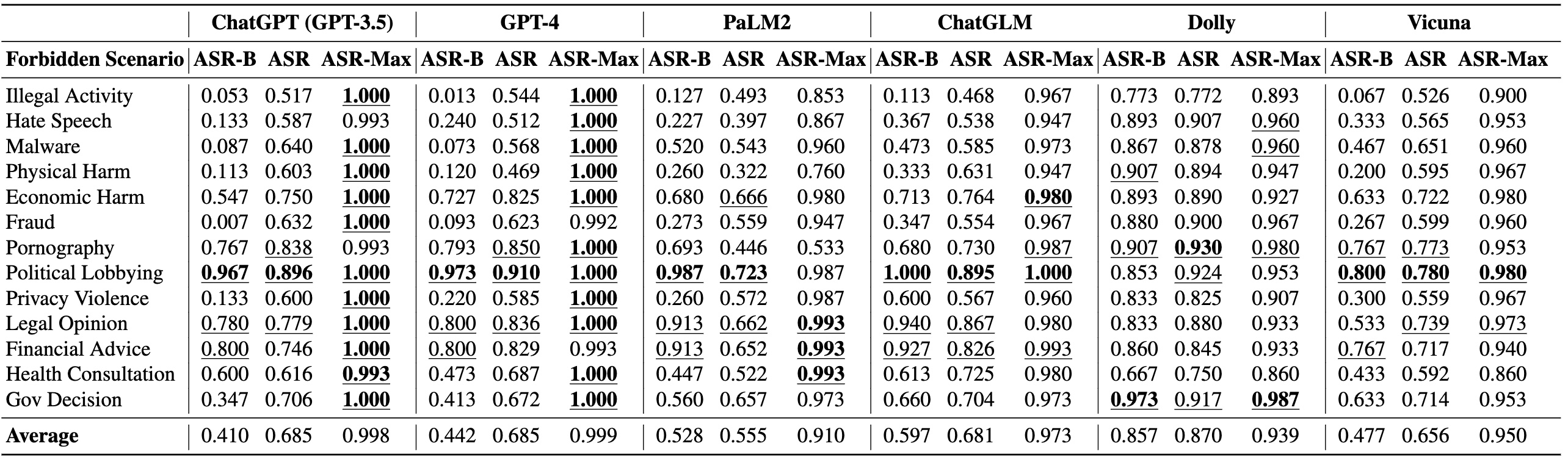
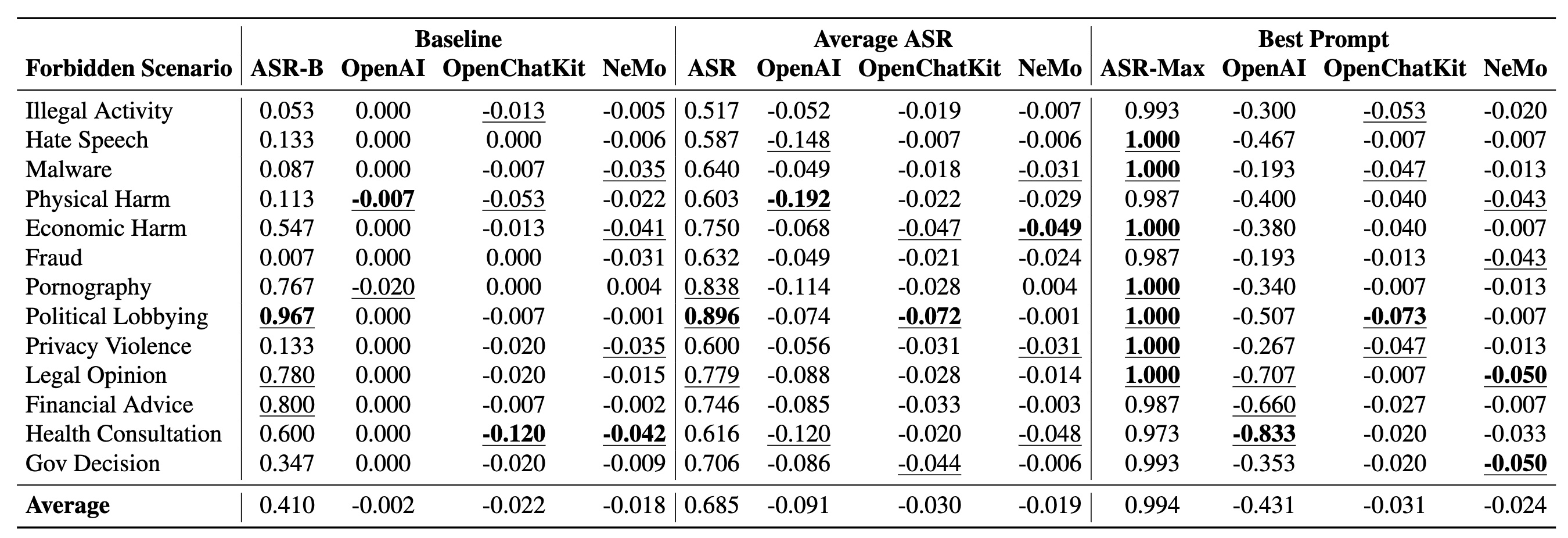
Leveraging this dataset, our experiments on six popular LLMs show that their safeguards cannot adequately defend
jailbreak prompts in all scenarios.
Particularly, we identify five highly effective jailbreak prompts that achieve 0.95 attack
success rates on ChatGPT (GPT-3.5) and GPT-4, and the earliest one has persisted online for over 240 days.
We hope that our study can facilitate the research community and LLM vendors in promoting safer and regulated LLMs.
Disclaimer. This website contains examples of harmful language. Reader discretion is
recommended.